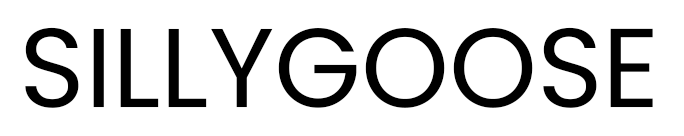

“In technology, size impresses but efficiency wins the war.”
Setting the Stage
There’s been plenty of chatter about whether DeepSeek “stole” from ChatGPT or reverse-engineered its model. But that noise misses the point. The real story is what DeepSeek actually brought to the table. To appreciate its leap forward, we first need to step back and understand how pre-DeepSeek AI operated and why that foundation mattered for its breakthrough.
AI is evolving at a dizzying pace, making it harder than ever to hold a clear picture of where it’s headed. After closely tracking the AI arms race, I’ve distilled the story into something accessible to both the casually curious and complete beginners, drawing on insights from Jeffrey Emanuel’s A Short Case for NVIDIA Stock. At the heart of this piece is the DeepSeek revolution explained in plain, straightforward language.
The future of AI isn’t just about building it bigger; it’s about building it smarter.
Tokens and Predictions
The LEGO Analogy
At its core, AI, like ChatGPT, works by breaking text into tokens small chunks of words. Think of tokens as LEGO bricks that AI puts together to create recognizable LEGO models. It first breaks down the input into individual bricks.
Example: If the question asked was What is the capital of France?
it tokenizes to
["What "," is " , " the "," capital", " of " , " France" ," ?"]
AI doesn’t “know” the answer it predicts it based on patterns from its training. It’s like picking the next LEGO piece in a half-built set. If the question is “the capital of France,” the most likely brick to follow is “Paris,” so that’s the guess. Yes, folks, you heard it here: AI guesses or predicts, to be precise. This prediction-based approach is powerful, but it has its limits.
Scaling against the data wall
 For many years, AI was improved by feeding it more data, using bigger models, and increasing computing power. The rule was simple: more LEGO (tokens), more Instructions (parameters), and more time and energy (compute power) = a more fantastic LEGO model (smarter AI). This is known as the pre-training scaling law.
For many years, AI was improved by feeding it more data, using bigger models, and increasing computing power. The rule was simple: more LEGO (tokens), more Instructions (parameters), and more time and energy (compute power) = a more fantastic LEGO model (smarter AI). This is known as the pre-training scaling law.
But there’s a catch. There is only so much data you can throw at it. Google Books and the Library of Congress combined produce around 7 trillion tokens. Anything after that has negligible returns, and we’re reaching that data wall a point where throwing more data at AI won’t make it more intelligent. High-quality data is scarce, and the brute-force approach may not be sustainable.
Inference, Hallucinations, and Chain of Thought
AI inference works like building a LEGO spaceship with a manual. It recognizes the pattern, predicts the next piece, and puts it together step by step based on past model builds. It doesn’t  memorize every spaceship but constructs one using learned patterns of what part would go next.
memorize every spaceship but constructs one using learned patterns of what part would go next.
However, inference can lead to AI hallucinations. When pieces are missing, AI improvises by adding bricks that look right but don’t belong or makes bricks from putty and stuffs them in there. The results may seem correct but are actually entirely false. Discernment is important.
Chain-of-thought (CoT) models take a different approach. Imagine building a complex LEGO model without instructions instead of just predicting the next piece, you think through each step, explaining why each piece fits before moving forward.
CoT reasoning makes AI more logical, increasing accuracy and avoiding prediction and guesswork. But, this uses a lot more energy (compute power and memory)
Expenses
When AI Bills Bite: The Hidden Costs Behind the Revolution
AI isn’t cheap to train and it’s getting pricier by the day. The race to build ever-more-powerful models has become a full-contact economic sport. Data centers specialized for AI processing are projected to require $5.2 trillion in capital by 2030, with total global data center investments reaching $6.7 trillion.
One jaw-dropping figure: individual AI training projects could consume 1–2 gigawatts of power today, and by 2030 that might climb to 4–16 GW nearly 1% of U.S. electricity capacity for a single model.
Then there’s the training itself. The cost curve is steep estimates show that building the most compute-intensive AI models has become 2.4× more expensive each year since 2016. By 2027, developing high-end models could exceed a billion dollars. Even more shocking, the cost of gathering and preparing training data often hidden from headlines can be 10× to 1,000× more than the raw compute cost.
And that’s without counting the energy, water, and infrastructure impact. Training GPT-3 alone released around 552 metric tons of CO₂ equivalent to running 123 gasoline-powered cars for an entire year.
Training doesn’t just cost money it costs resources, sustainability, and access. Only the wealthiest players can afford to compete, making AI innovation increasingly unequal.
Training these models requires massive computing power, expensive GPUs, and vast data centers. Once a model is trained, should we keep using it? Build the next, and the next, and the next? Or scrap it for a newer, better version with the latest tech? This cycle is wasteful, costly, and unsustainable and it raises the price of entry into the AI domain to staggering levels.
Deep Seek: A Shift in Thinking
Deep Seek challenges this model by prioritizing efficiency over brute-force scaling a game-changer. So, instead of making AI bigger, the future of AI must be making it smarter with fewer resources. Understanding these key shifts will help you see where the industry is headed, whether you’re just getting into AI or following every new breakthrough. So, what has Deep Seek brought to the Table?
Summary
For the ones in a hurry
Think of AI as building LEGO models. Old-school AIs like ChatGPT kept adding more and more LEGO bricks (data) and bigger instruction manuals (computing power) to make smarter models. But at some point, adding more stopped helping like trying to improve a LEGO car by just dumping more bricks on it.
DeepSeek came in with a smarter toolbox. Instead of piling on, they used sharper tools and clever tricks: printing blueprints in HD only where needed (mixed precision), typing multiple words at once instead of one (multi-token prediction), and having a group of expert “teachers” who only speak when their subject is relevant (Mixture-of-Experts).
The model even taught itself to double-check its work and stay on topic like a student learning to think before answering (Long Chain-of-Thought) and to stick to one language in the same sentence (language consistency).
DeepSeek innovations
For the more technically inclined
Here I’ve broken down the 7 innovations that DeepSeek brought to the table and have yet to be bested.
- Mixed precision Framework,
- Multi-token prediction system,
- Multi-head latent Attention,
- Mixture-of-Experts (MOE) transformer architecture,
- GPU Dual-pipeline algorithm,
- Long Chain of thought with Data served cold,
- Language consistency
Buckle up; this is going to get technically bumpy
DeepSeek surpassed multiple challenges that plagued the AI world. As the story goes, the engineers and mathematicians at DeepSeek had to work with financial and hardware constraints, which led to the development of a highly efficient AI model and begged the invention of new techniques for streamlined resource use.
1. Mixed precision
Training Smarter, Not Harder
One of DeepSeek’s boldest moves was rethinking precision itself. Traditional AI training leaned on full precision 32-bit numbers the equivalent of 4K blueprints for building a model. More detail meant more accuracy, but also more memory, more power, and a much bigger bill.
DeepSeek flipped the script. They went with 8-bit floating-point numbers (FP8) think 1080p resolution throughout the training process. At first, this sounds like a downgrade.
But FP8 isn’t just “smaller” numbers its design can store both extremely tiny and extremely huge values, just with slightly less fine-grained precision. DeepSeek used a mathematical sleight of hand to keep the most important details sharp where they mattered like preserving “4K” clarity for fine work while letting broader strokes run in “1080p.”
This delivered massive memory savings and made it possible to train across thousands of GPUs without the usual overhead. Crucially, they didn’t train in 32-bit and then compress (which risks losing quality) they trained natively in FP8, baking efficiency into the foundation.
The result? Fewer GPUs. Lower costs. Bigger models for less. In an industry where labs spend millions just to keep up with compute demands, this isn’t just an optimization it’s a blueprint for a more scalable, sustainable AI future.
One of DeepSeek’s biggest breakthroughs was its mixed precision framework. Their approach wasn’t about throwing more power at the problem it was about training smarter, not harder. A key part of that was mixing precision levels strategically, marking a major shift from traditional AI training methods.
2. Multi-token Prediction
Doubling Speed Without Sacrificing Quality
Traditional transformer-based AI models generate text one token at a time like typing on your phone where autocorrect suggests only the next word. It’s accurate, but slow when generating long responses.
DeepSeek rewrote the playbook. Instead of predicting just one token at a time, they engineered a way to predict multiple tokens simultaneously, without losing the precision of single-token inference.
At first glance, this sounds risky more predictions at once should mean more errors. But DeepSeek preserved the full causal chain of predictions, ensuring each token still depended on the ones before it. No blind guessing just structured, context-aware output.
The result? 85–90% accuracy on these additional token predictions, with inference speed nearly doubled. That means faster responses, reduced compute load, and an AI that can think ahead without tripping over its own logic.
3. Multi-Head Latent Attention
Smarter Memory, Faster AI
One of the biggest bottlenecks in AI training is memory usage, especially when it comes to key-value (KV) indices. Think of KV indices like an address book: when AI processes text, it doesn’t just memorize words it records where they are and how they relate to each other. These “addresses” guide the model on which past words to revisit when predicting the next token. 
The catch? Storing these indices eats memory fast. A high-end GPU may have 96GB of VRAM, but traditional full-precision storage of KV indices can chew through it in no time. It’s wasteful, but until now, it was the industry norm.
DeepSeek’s Multi-Head Latent Attention (MLA) changes the rules. Instead of storing every microscopic detail, MLA compresses KV indices without losing essential information and crucially, this isn’t a post-processing hack. The compression is built directly into the model’s training.
Why it’s a breakthrough:
- Differentiable compression trained alongside the model itself, not bolted on afterward.
- Noise filtering the model learns to keep only what matters, ditching irrelevant clutter.
- Lower memory footprint freeing resources for faster, more scalable performance.
This means DeepSeek’s models aren’t just lighter they’re sharper. While others hoard every data point, DeepSeek keeps only the most valuable, leading to faster inference and smarter attention.
4. Mixture-of-Experts (MOE)
Smarter not bigger

Picture a massive school with hundreds of teachers, each an expert in a different subject. When a student asks a question, they don’t consult the entire staff only the relevant experts step forward, while the rest stay in the lounge. That’s the logic behind Mixture-of-Experts (MoE) models. Instead of one massive AI brain trying to handle everything, MoE uses many smaller “expert” sub-models but only the ones best suited for the task are activated.
Why this matters:
- More knowledge, less clutter the model can store vast amounts of information without dragging down performance.
- Energy savings only the necessary experts are active at a time.
- Lower costs reduced computational load means cheaper, faster inference.
Take DeepSeek V3 as an example: it has 671 billion parameters (experts) in total, but only 37 billion are active at any given time. That’s larger than LLaMA 3 in capacity but light enough to run on just two consumer-grade NVIDIA 4090 GPUs.
The result? A model with massive knowledge capacity that’s still lean, affordable, and lightning fast.
5. GPU Dual-Pipeline
The Two-Lane Highway

Imagine a busy road where cars (data) need to move quickly. On a single-lane road, traffic stalls whenever there’s a delivery stop. Add a second lane, and now one handles the flow (computation) while the other manages deliveries (communication) no more bottlenecks. That’s exactly what DeepSeek’s Dual-Pipeline algorithm does for GPUs. Instead of pausing to switch between tasks, GPUs handle computation and communication in parallel, keeping both “lanes” active.
In practice:
- 20 GPUs handle communication tasks.
- The rest focus purely on heavy computation.
The payoff? Training runs far more efficiently, squeezing maximum performance out of hardware and cutting AI training time significantly.
6. Long-chain-of-thought
Reasoning Like a Human

The DeepSeek R1 model shocked the AI world by outperforming giants like Anthropic in step-by-step reasoning, the kind humans use to solve problems. The twist? DeepSeek made its tools fully open-source, like handing out a spaceship blueprint so anyone can build and improve it. Instead of training by memorizing millions of examples, DeepSeek rewarded good reasoning moves and let the model figure out the rest. It learned to:
- Break problems into steps.
- Double-check its work.
- Spend more “mental energy” on harder problems.
They also tackled a major flaw in most AIs, chasing points even with wrong answers, by designing a reward system that values how you solve the problem, not just the final result.
The breakthrough came with Cold-start data: a small set of high-quality examples used to guide training from day one. Over time, the model learned to pause, sense when it might be wrong, and try a new approach a self-correction skill no one explicitly taught it
7. Language consistency

Staying Fluent from Start to Finish
Older step-by-step AI models often stumbled into language drift, starting a response in English and finishing in gibberish or a different language. Imagine reading a recipe that begins in English but halfway through switches to Mandarin, frustrating and confusing.
DeepSeek solved this with a smart language check during training. Instead of only rewarding correct answers, the model was also nudged to stick to one language throughout its reasoning. Think of it like training a dog not just to fetch, but to always bring back the same type of stick every time.
The trade-off? A slight dip in raw performance, but a huge leap in clarity and readability. The result is output that stays coherent, fluent, and consistent from the first word to the last.
Riding the AI Wave
Further Reading & Watching on the AI Shift
- Andrej Karpathy – Lecture: Scaling AI Efficiently: “Insights on maximizing AI performance while minimizing computational costs.”
- DeepSeek AI – DeepSeek GitHub Repository: “A collection of open-source AI tools, models, and research resources.”
- Epoch AI – The Cost of Training AI Models: “An in-depth analysis of financial, environmental, and technical costs in AI model training.”
- Hugging Face Blog – Mixture-of-Experts Explained: “A clear guide to how MoE architectures improve AI efficiency and scalability.”
- Jared Kaplan et al. – The Scaling Laws for Neural Language Models: “Foundational research showing how performance scales with model size and data.”
- Jeffrey Emanuel – A Short Case for NVIDIA Stock: “An investor’s perspective on NVIDIA’s role and growth potential in the AI era.”
Final Thoughts
Building Wiser, Not Just Bigger
DeepSeek represents a genuine paradigm shift in AI. Instead of following the industry trend of building ever-bigger models and hoping for better results, they rewired the engine for performance. Every innovation was deliberately engineered to trade unnecessary complexity for smarter, more efficient thinking without sacrificing accuracy.
The lesson is clear: the future of AI isn’t about sheer size; it’s about precision, efficiency, and intelligent design. DeepSeek proved that by working smarter, not harder, you can outpace the giants and redefine what’s possible.
References
- Kaplan, J., McCandlish, S., Henighan, T. (2020): Scaling Laws for Neural Language Models
- Emanuel, J. (2025): A Short Case for NVIDIA Stock
- MIT News (2025):Generative AI’s Environmental Impact
- Scientific American (2023): A Computer Scientist Breaks Down Generative AI’s Hefty Carbon Footprint
- Wharton School of the University of Pennsylvania (2024): The Hidden Cost of AI: Energy Consumption
- Columbia Climate School (2023):AI’s Growing Carbon Footprint
- Smartly.ai (2024):The Carbon Footprint of ChatGPT: How Much CO₂ Does a Query Generate?
- MarketWatch (2025):Does DeepSeek Spell Doomsday for NVIDIA and Other AI Stocks? Here’s What to Know
- Business Insider (2025):Meta’s Yann LeCun Says Scaling AI Models Won’t Make Them Smarter

